记录,备忘…
LRU
LRU,即Least Recently Used(最近被使用得最少的),是一种常见的缓存淘汰策略,意思是把缓存中最久未被使用的值优先考虑淘汰。而基于这种淘汰策略的缓存就是所谓的LRU Cache。
LinkedHashMap–现成的LRU
Java中的LinkedHashMap,可以简单理解为LinkedList+HashMap,Java中的LinkedList为双向链表,可以维护一个逻辑,就是按一个方向把元素按一个维度来线性排序:表头总是指向当前最近访问的节点,表尾总是指向当前最久未被访问的节点,也就是LRU。
LinkedHashMap数据结构示意图
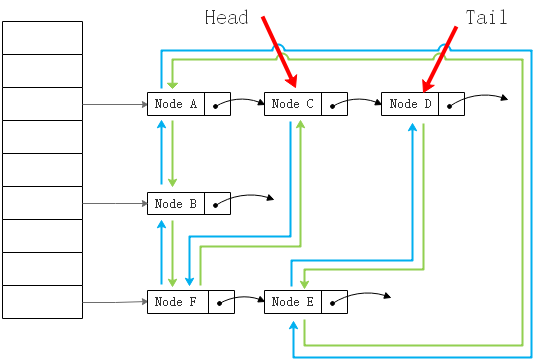
从HashMap角度
基于HashMap角度看,就是加了双向指针的HashMap:
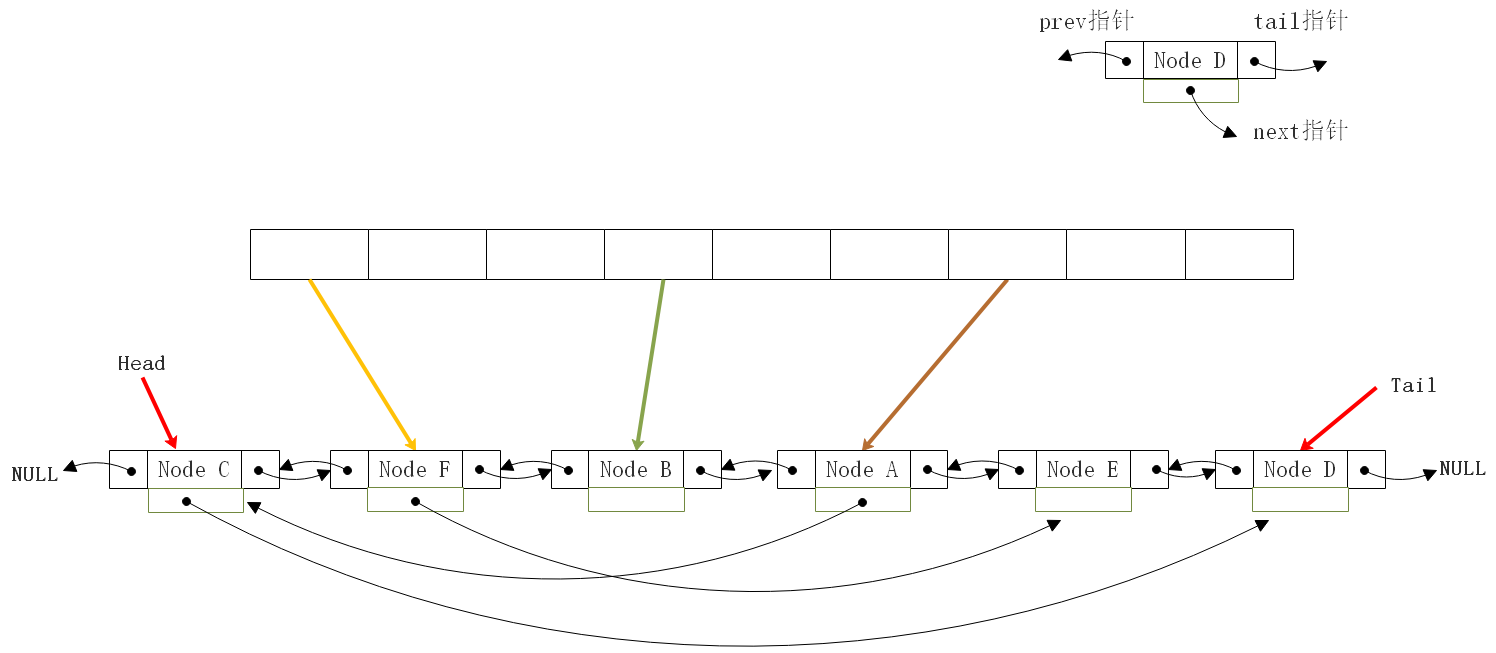
从LinkedList角度
基于LinkedList角度看,可以简化为链表加上散列:
Entry节点
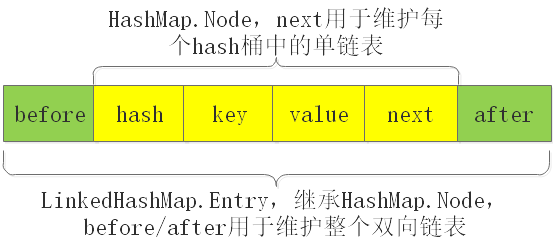
以上仅仅是帮助理解的示意图,并非严谨数据结构图
双向链表简单实现
基于HashMap,再实现双向链表的基本操作:
- 添加操作:由于是添加操作,就意味着可能出现容量不够,也就是链表已满,那么就要执行淘汰策略:删除最久未被访问的节点。
- 删除操作:把指定节点移除掉,移除前需调整涉及到的各个指针的指向,包括当前节点的前节点的后指针、后节点的前指针,链表的头指针、尾指针。
- 请求读取元素:
- 命中:更新表头指针,即把当前命中的节点作为头节点;
- 未命中:如果是单纯只读操作,而又未命中,则不会引起任何变化。
[LRUCache.java](https://github.com/FGU123/LRU/blob/master/src/main/java/com/xu/tlab/service/impl/self/LRUCache.java)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
|
public class LRUCache<K, V> {
private int capacity = 1 << 30;
private Map<K, Node> map = null;
private Node head;
private Node tail;
public LRUCache() {
map = new HashMap<K, Node>( capacity );
}
public LRUCache( int capacity ) {
this.capacity = capacity;
map = new HashMap<K, Node>( capacity );
}
public class Node {
private K key;
private V value;
private Node prev;
private Node next;
}
public void put( K key, V value ) {
Node node = map.get( key );
if( null == node ) {
node = new Node();
node.key = key;
}
node.value = value;
if( removeEldest( node ) ) {
removeTail();
}
map.put( key, node );
moveToHead( node );
}
protected boolean removeEldest( Node eldest ) {
return map.size() >= capacity;
}
private void removeTail() {
if( tail != null ) {
remove( tail );
}
}
public void remove( Node node ) {
if( tail == node ) {
tail = tail.prev;
}
if( head == node ) {
head = head.next;
}
if( node.prev != null ) {
node.prev.next = node.next;
}
if( node.next != null ) {
node.next.prev = node.prev;
}
map.remove( node.key );
}
public V get( K key ) {
Node node = map.get( key );
if( node != null ) {
moveToHead( node );
return node.value;
}
return null;
}
private void moveToHead( Node node ) {
if( tail == null || head == null ) {
head = tail = node;
return;
}
if( head == node ) {
return;
}
if( tail == node ) {
tail = tail.prev;
}
if( node.prev != null ) {
node.prev.next = node.next;
}
if( node.next != null ) {
node.next.prev = node.prev;
}
head.prev = node;
node.next = head;
node.prev = null;
head = node;
}
|
为什么使用双向链表
队列行不行?
不行,队列只能做到先进先出,但是如果是访问排在中间的数据,此时无法把中间的数据移动到顶端。
单链表行不行?
如果用单链表,能保证实现最新或最热节点放到一侧,但是最久未被使用要放到另一侧,如果只有表头一个指针,那么获取尾节点,则需要从头指针一直到尾,遍历整个单链表,而双向链表同时还有尾指针,尾指针可以帮助直接定位到最后一个节点。更关键的是,在做移动/删除节点的操作的时候,当需要把当前节点的前节点的后指针指向为后节点时(node.prev.next=node.next),获取前节点的操作就只需要透过前指针获取即可,但如果是在单链表中,则需要进行更费时的遍历查找操作来获取到前节点。
为什么使用HashMap
HashMap是用于降低寻找节点的时间复杂度的。主要是因为可以快速定位(散列查找的最优时间复杂度是O(1))。配合LinkedList,定位+移位节点的操作的效率变得更高。
线程安全
为了保证Cache的读写在多线程下正确,也就是线程安全,最简单粗暴的就是给引起指针变化的操作及遍历操作全加锁。