背景
Aviator简介
Aviator是一个高性能、轻量级的基于Java实现的表达式引擎,它动态地将String类型的表达式编译成Java ByteCode并交给JVM执行。
Aviator 的基本过程是将表达式直接翻译成对应的 java 字节码执行,整个过程最多扫两趟(开启执行优先模式,如果是编译优先模式下就一趟),这样就保证了它的性能超越绝大部分解释性的表达式引擎,测试也证明如此;其次,除了依赖 commons-beanutils 这个库之外(用于做反射)不依赖任何第三方库,因此整体非常轻量级,整个 jar 包大小哪怕发展到现在 5.0 这个大版本,也才 430K。同时, Aviator 内置的函数库非常“节制”,除了必须的字符串处理、数学函数和集合处理之外,类似文件 IO、网络等等你都是没法使用的,这样能保证运行期的安全,如果你需要这些高阶能力,可以通过开放的自定义函数来接入。因此总结它的特点是:
- 高性能
- 轻量级
- 一些比较有特色的特点:
○ 支持运算符重载
○ 原生支持大整数和 BigDecimal 类型及运算,并且通过运算符重载和一般数字类型保持一致的运算方式。
○ 原生支持正则表达式类型及匹配运算符 =~
○ 类 clojure 的 seq 库及 lambda 支持,可以灵活地处理各种集合- 开放能力:包括自定义函数接入以及各种定制选项
Aviator表达式的使用场景
在公司的一个项目,主要是基于配置来定义和实现不同的埋点接口,当中涉及部分表达式求值的配置项,使用了Aviator来实现所配置的表达式。
该项目使用了Aviator一段较长的时间,期间一直保持稳定服务。直到最近一次突然线上出现内存膨胀问题。
问题暴露
2021年2月21号收到告警服务请求成功率下降,可用性变低
问题处理
即时处理
接收到告警后,开发迅速响应处理问题,通过日志快速排查到是OOM问题,内存爆满,在服务器上dump内存日志后并重启机器,尽快恢复线上服务正常。
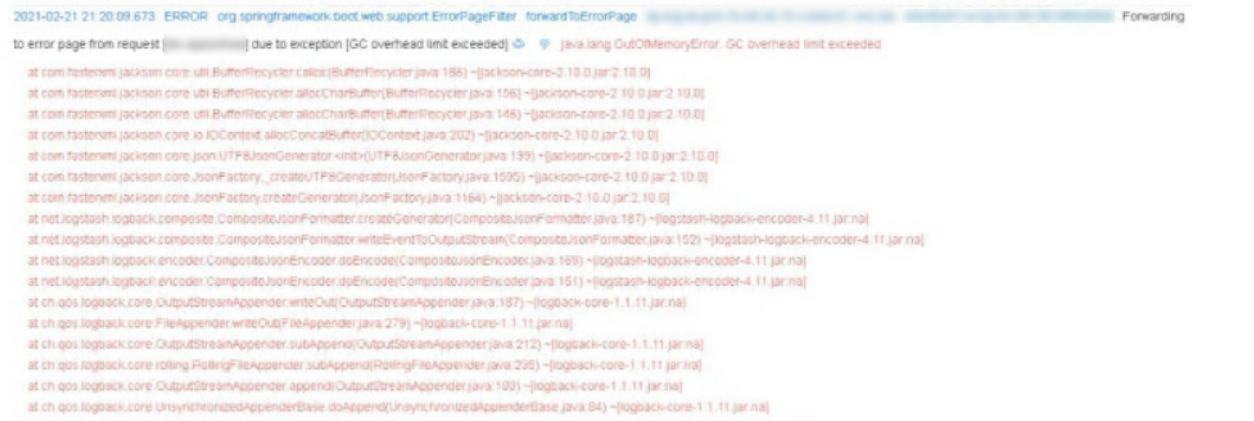
原因定位及分析
通过日志观察得知服务在当天某个时间点左右开始出现频繁fullGC,并且日志里打印了类似GC回收无效/低效(GC overhead limit exceeded)的异常堆栈
从该报错信息可以看出,GC并不能有效地回收内存,从而导致频繁fullGC

要解决这个问题,需要先分析到内存中的对象情况,思路在于如何解答这两个问题:
1.哪类对象占用了最多的内存?
2.这些对象是在哪部分代码中分配的?
通过运维同学帮忙在线上dump出的内存快照,使用Jprofiler分析,看出内存当中,存在一个静态对象(com.googlecode.aviator.AviatorEvaluationInstance),这个对象占用内存比例极高(98%),这解答了上面第一个问题
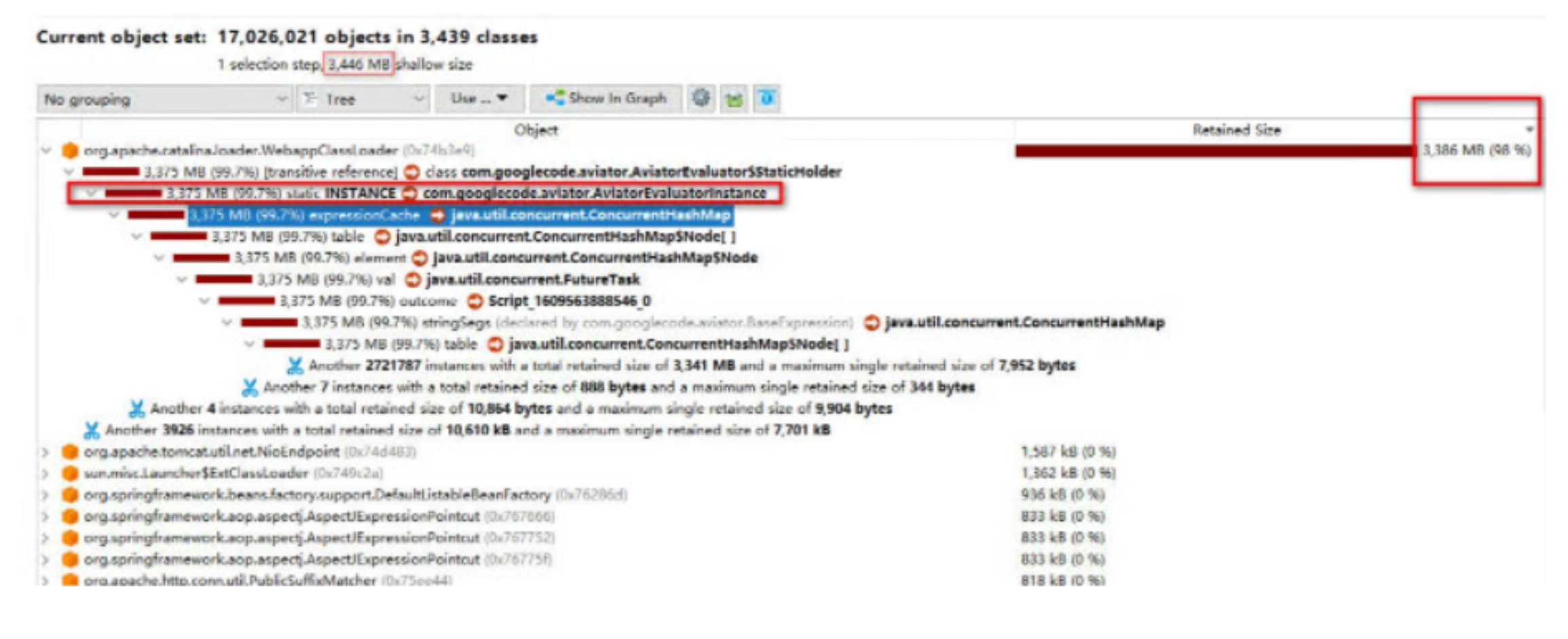
再看这个对象的引用链,我们看到了这个静态对象的对外引用(outgoing reference,对其它对象的引用)情况,从逐层的引用情况看出来,当中有两层ConcurrentHashMap,其中第二层的ConcurrentHashMap被怀疑正是当时内存占用率飙高的原因所在。我们通过引用链,翻查框架的源码,找到了这个对象和它所引用的两层ConcurrentHashMap,最终解决了上面第二个问题。
一开始,通过翻阅源码及相关文档,尝试理解这个框架的代码设计,尝试解答为什么这里会设计两个缓存对象。
排查过程中,在GitHub上搜查这个框架相关的问题,找到了一个类似的内存被占满的issue,循环调用AviatorEvaluator.execute的时候会出现问题 , 但发现这个issue讨论的是Aviator框架在默认不使用缓存的模式下会在每次调用执行引擎时都实时编译表达式,并且编译后的表达式不是存放在堆内存而是在方法区,这会导致堆外内存占用高,并且由于实时编译,当高并发或高频调用时CPU占用也会偏高。这跟我们线上所遇到的问题还不是同一个问题,但这给了我们一个排查方向,把问题聚焦到了AviatorEvaluator的执行过程的代码,继而聚焦到了当中的两层ConcurrentHashMap缓存的设计。
最后,在官方文档及对照框架源码,个人理解这个框架的两层ConcurrentHashMap缓存的设计,可能有以下的涵义:
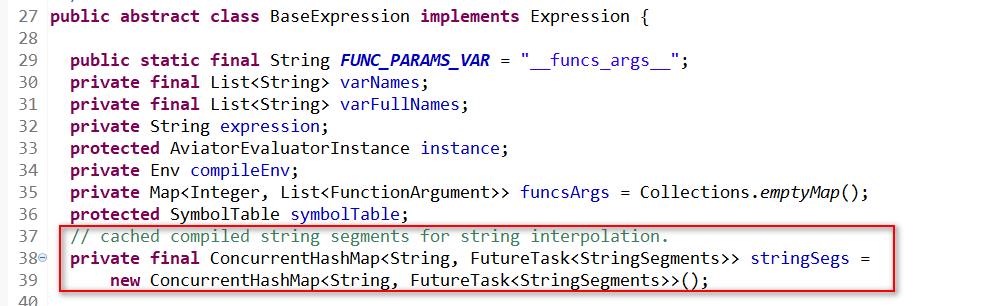
第一层ConcurrentHashMap缓存:是为了对不带实参的源表达式(Text Expression)所对应的线程任务列表做缓存,key是Text Expression,value则是FutureTask,用于直接获取不同的源表达式的执行任务情况;
第二层ConcurrentHashMap缓存:Expression接口的基础实现类BaseExpression中,一个名为stringSegs的变量,是每个线程任务(FutureTask)里边,执行过的带实参的表达式的任务缓存,用于直接获取同一个源表达式不同实参组合的执行任务,目的是当同一个表达式的同一组入参值在调用第二遍执行引擎时,可以避免引擎重复执行表达式的运算过程(直接调FutureTask.get()方法而不用再次调FutureTask.run()方法)
举个例子,假设我们有一个表达式,声明为expression = a + b / c;
当我们在传入a=1,b=2,c=3去调用表达式引擎时,引擎内部会先使用第一层ConcurrentHashMap存储:(key1: (String)"a+b/c", value1: (FutureTask 而因为第二层的ConcurrentHashMap缓存是以带实参的表达式作为key的,而且作者并没有设置第二层缓存的上限值(第一层缓存可以指定为LRUCache指定key上限,但第二层只有一个没指定key容量上限的ConcurrentHashMap实现),那么随着不同的请求参数值传入,形成不同的实参值组合,导致ConcurrentHashMap的key不断增多,而AviatorEvaluationInstance是静态变量,一直常驻内存,即便GC之后也不会被回收,这便是产生了缓存膨胀、内存爆满的根本原因所在。而我们的业务使用场景,就是每个请求一进来都会带一个UUID型的请求ID(可以认为实参组合的数量是无穷的),最终酿成了这次缓存膨胀的故障。
解决方案
既然GC无效的问题,归根到底是由于第二层ConcurrentHashMap缓存导致的,自然地,一开始想到的最简单直接的解决方案,便是不使用缓存或者删除第二层的ConcurrentHashMap即可。但如上文所提到的一个issue,循环调用AviatorEvaluator.execute的时候会出现问题 ,不使用缓存将会导致方法区增大(对外内存占用率增大)、且CPU占用率增高,这并不可行。
另一方面,通过翻查代码,发现了这个名为stringSegs的ConcurrentHashMap缓存,并没有开放API供上层调用获取该缓存对象,这下,似乎只能从它的上层引用–第一层缓存下手了,因为第一层缓存持有对第二层缓存的引用,而第一层缓存被一个静态变量所引用,所以无法释放这两层缓存的引用,导致GC后无法回收。那么只要我们清掉第一层的缓存,自然第二层也会被清理。再次review代码,发现框架有针对第一层缓存对外开放API提供直接清理这层的口子:
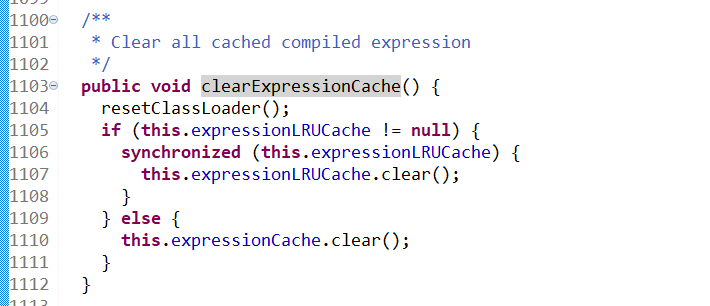
而翻查Aviator这个框架的官方说明文档,找到了作者对这个框架的最佳实践指导,包括高版本针对第一层缓存的优化,可以指定使用的缓存模式为LRUCache来避免上文提到的issue(方法区缓存膨胀)及源表达式数量过大导致的堆内存膨胀:
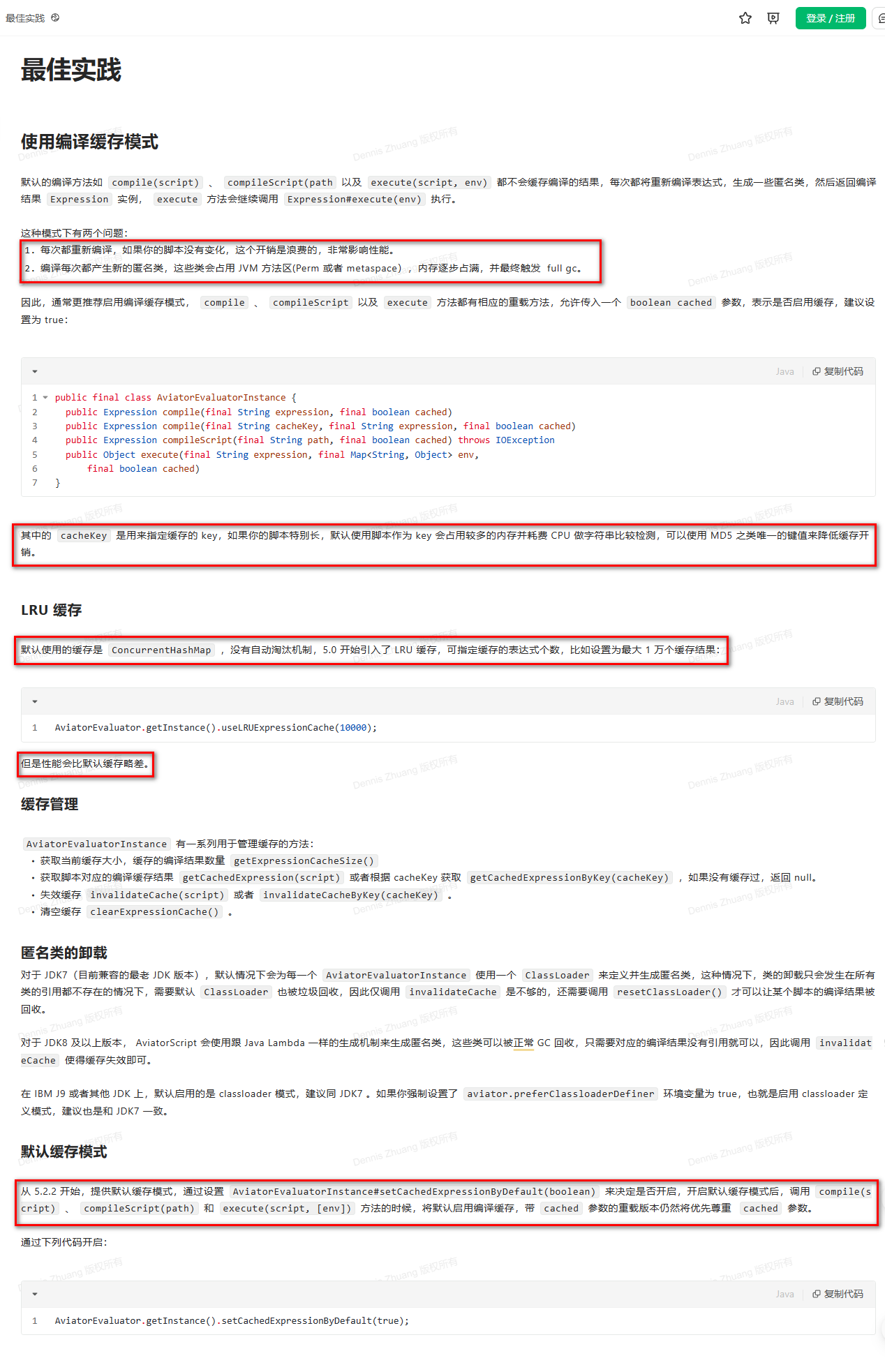
于是,最终决定了针对这个问题的优化方案是,对缓存进行两方面的优化处理:
- 改用LRUCache指定表达式缓存,指定源表达式的key的上限,代替框架默认的ConcurrentHashMap
- 设立定时任务,对表达式缓存进行定时清理,从而避免源表达式缓存(第一层)、带实参的表达式缓存(第二层,主要目的就是为了清理这一层)的膨胀问题
1 |
|
附录
扫描二维码,分享此文章