背景
Dubbo服务上下游情况
1.背景
公司项目,Dubbo上游服务在元旦前夕流量突增,为应对突增流量带来的压力,上游(consumer)节点服务临时扩容一倍机器数量,而扩容操作完成之后,后续出现下游的部分(provider)节点服务器抛出异常,表现为下游机器的CPU使用率飙高达至大于100%的水平(远高于正常水平),机器在运行一段时间后,出现堆内存溢出(Out Of Memory: Java Heap Space),此时机器实际上已经不能正常服务于上游,继而机器很快地会被服务器容器(docker)预设的OOM killer程序强制杀死JVM进程,服务器所在容器的实例进入“未就绪”状态,随后实例被销毁、回收,继而导致上游调用超时或失败并且引起监控侧的告警,影响业务正常运行。
问题暴露
问题表现有二:
现象1:重启下游机器后,CPU使用率瞬间飙高,超100%以上(约5个线程并行占用CPU 70% ~ 100%,因为是docker容器虚拟化环境,所以top命令显示出来简单合计为约350% ~ 500%的占用率)
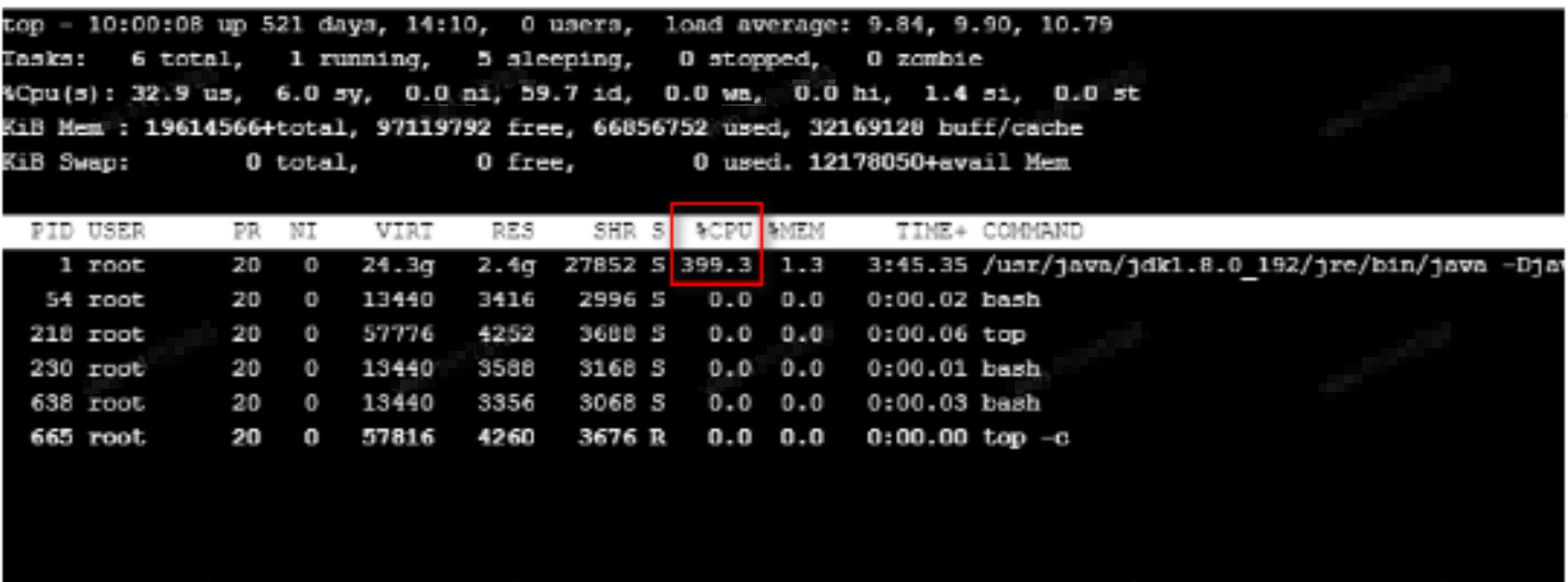
现象2:服务器在持续高负载下运行一段时间后,日志一直打印OOM(堆溢出)错误,继而机器进入“未就绪”状态(不可服务状态)
–堆栈截图过于模糊,图略
现场处理
即时通过Dubbo服务治理将下游出现问题的机器禁用,禁止上游机器流量进入下游的问题机器,将有问题的机器保留现场,并且由于JVM启动参数有配置OOM自动生成并导出dump堆栈(-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/data),OOM文件作为问题排查的线索。
原因定位及分析
初时因为出现OOM,我们开发团队的排查方向很自然地被带到了分析内存,由Dump文件入手分析当时内存状态。
但分析内存过程中,出现排查难的困境,主要原因在于:
内存快照文件(Dump文件)过大:Dump文件反映的是服务器内存的状态,其文件内容就是当时整个堆内存的快照,而我们的服务器分配的内存是4G(正常水平),所以导出的文件有4G之大。这为文件的导出、下载等带来各种实质操作上的难度。
Dump文件只在容器里短暂存留:由于我们的服务器配置了OOM的自动Dump配置,当发生OOM时系统会自动导出Dump文件,但由于运维机制,此时机器很快会被OOM Kiler程序强制杀死JVM进程,服务器所在容器实例进入“未就绪”状态,不多久该服务器实例即会被销毁、回收。故Dump文件如果不及时导出(上传至云盘或外部存储),那么Dump文件将不复存在。
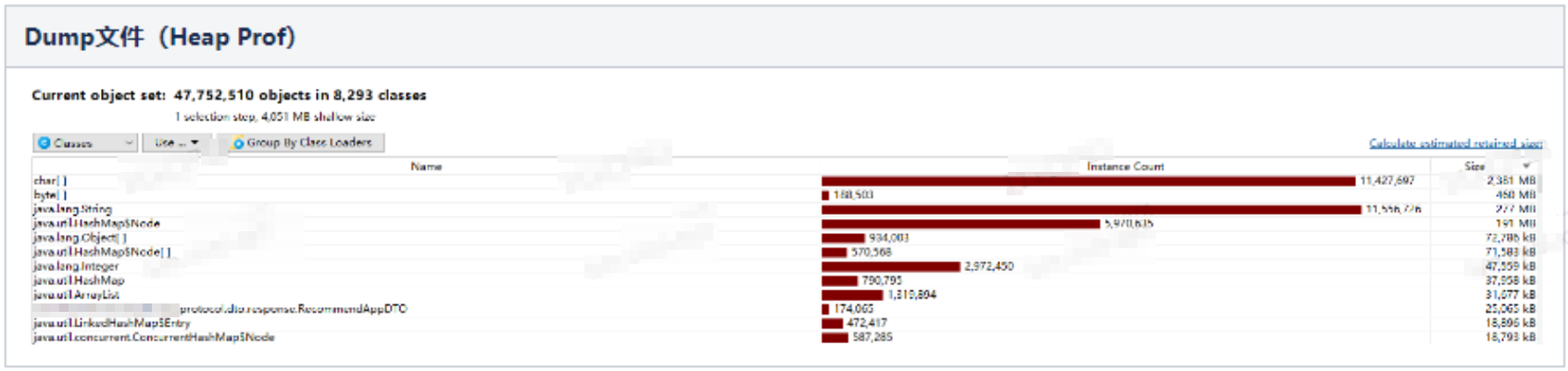
在多番努力尝试下,终于导出Dump文件,但此时发现,对内存的分析,所得到的有用信息,并不多。我们充其量只知道,当时对堆内存占用较多的一些实例对象,都是些正常的基础对象实例(char数组、byte数组、string、hashmap等)、业务对象实例等。
于是转到直接正面排查CPU飙高的问题,通过线上诊断工具(Arthas工具,由于线上容器实例默认无安装Arthas,此前实际上还花费了些时间折腾了一阵子工具的安装配置)来直接定位到当时占用CPU最高的3条线程,发现3条线程的调用栈均一致(事实上是不止3条,当时有5条类似的线程,都在跑同样的任务),如下图:
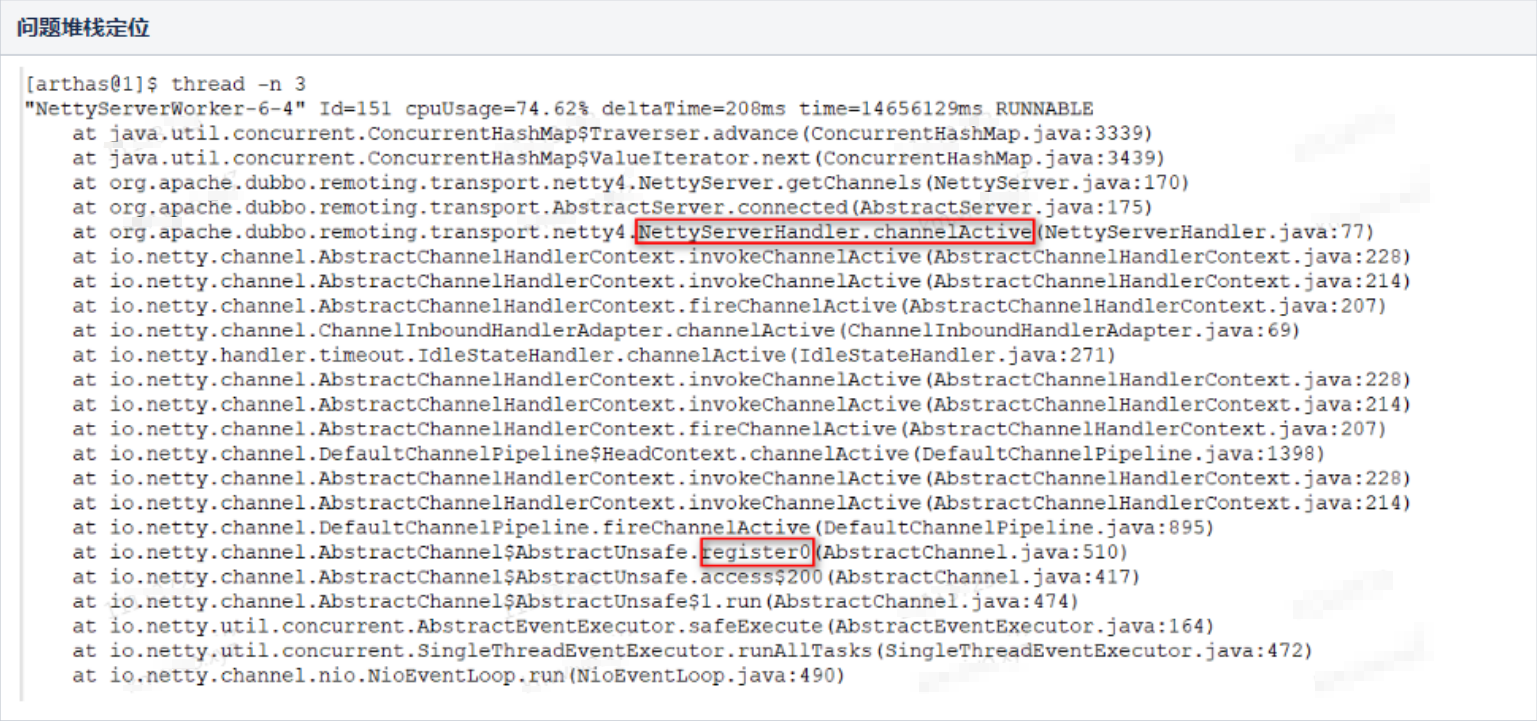
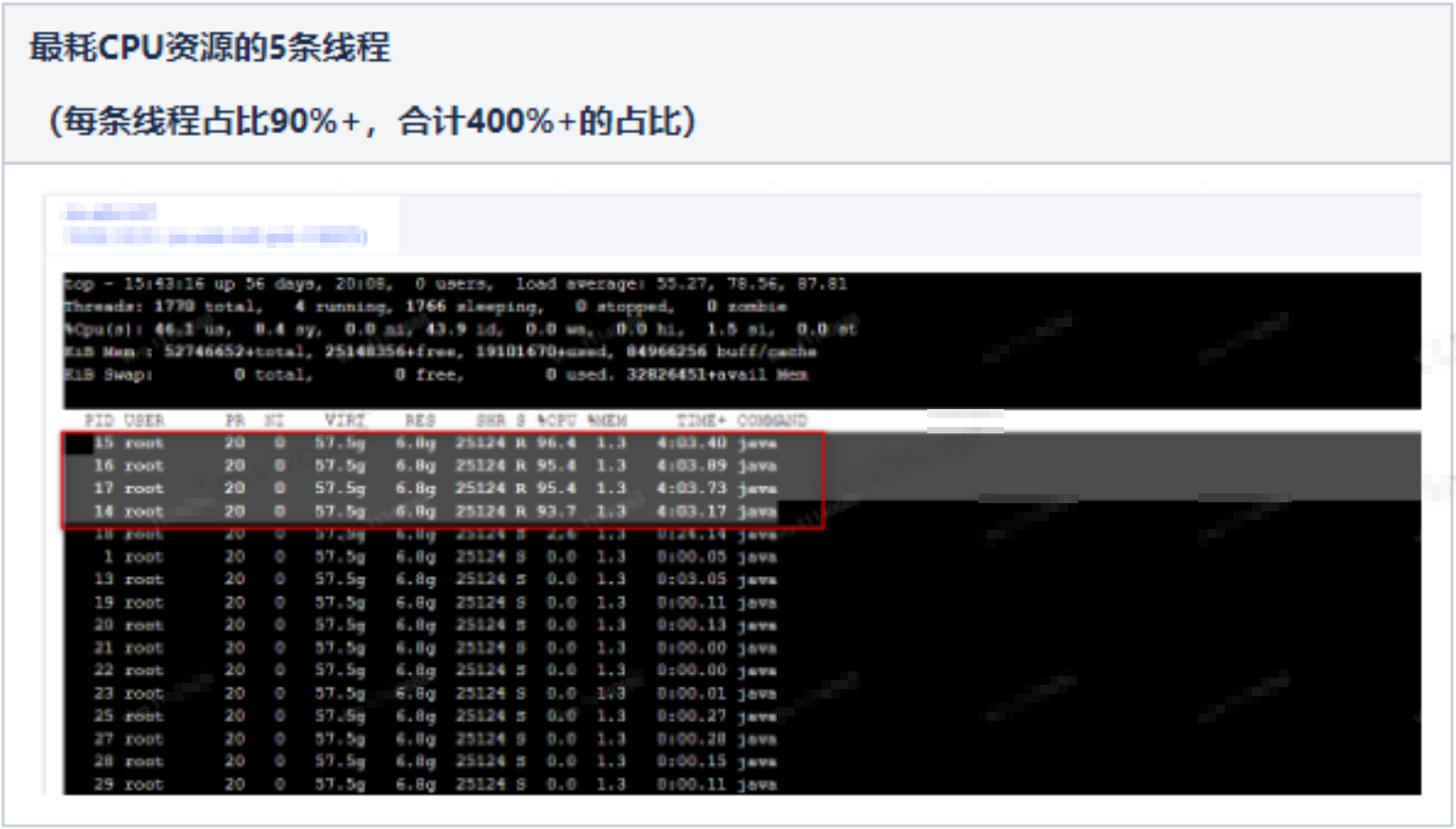
通过Arthas列出这条最耗CPU资源的线程正在跑的堆栈,与我们导出的火焰图(性能分析图)所描述的堆栈,也完全一致。
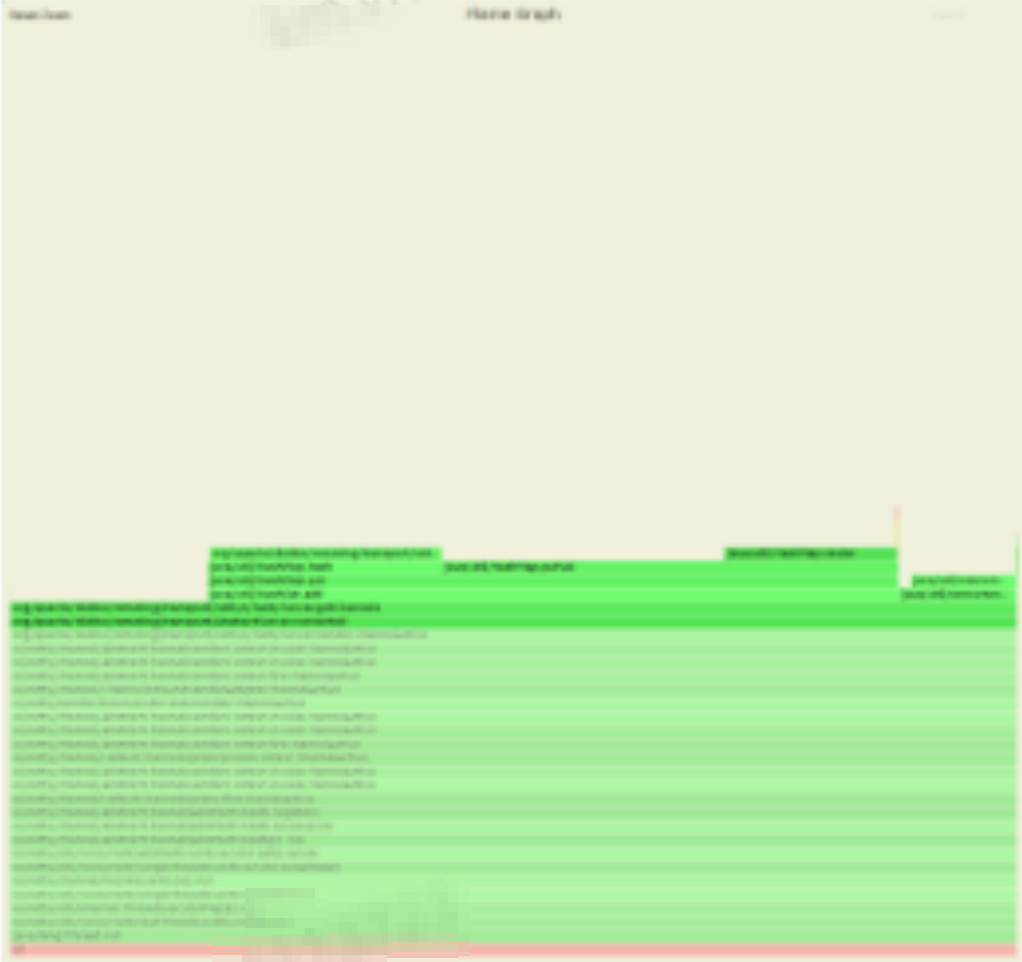
这段堆栈信息,所指向的代码,并非业务代码,而是Dubbo微服务框架的代码。
Dubbo代码分析:NettyServerHandler创建连接的过程
io.netty.channel.AbstractChannel.AbstractUnsafe.register(EventLoop, ChannelPromise)
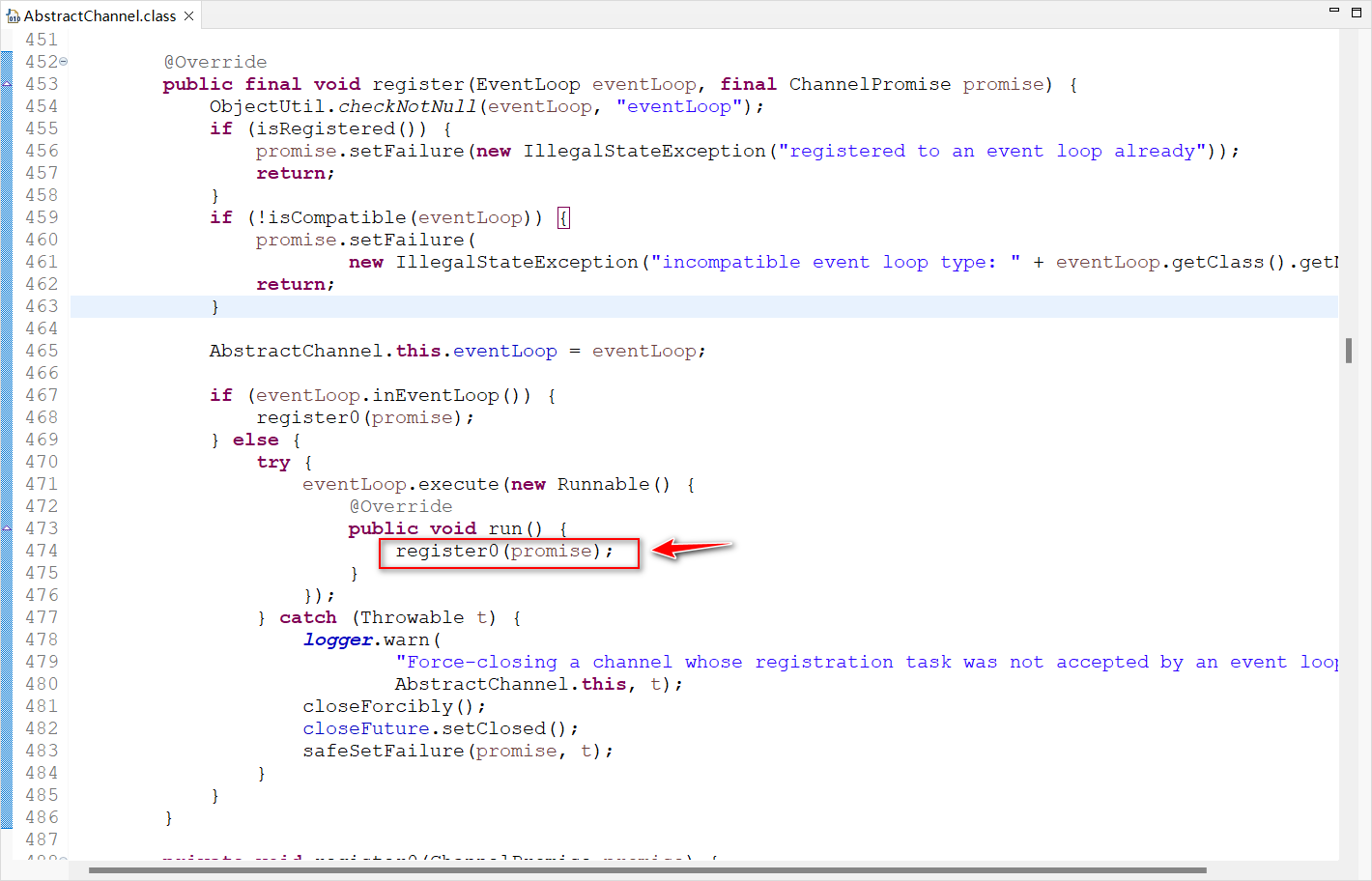
io.netty.channel.AbstractChannel.AbstractUnsafe.register0(ChannelPromise)
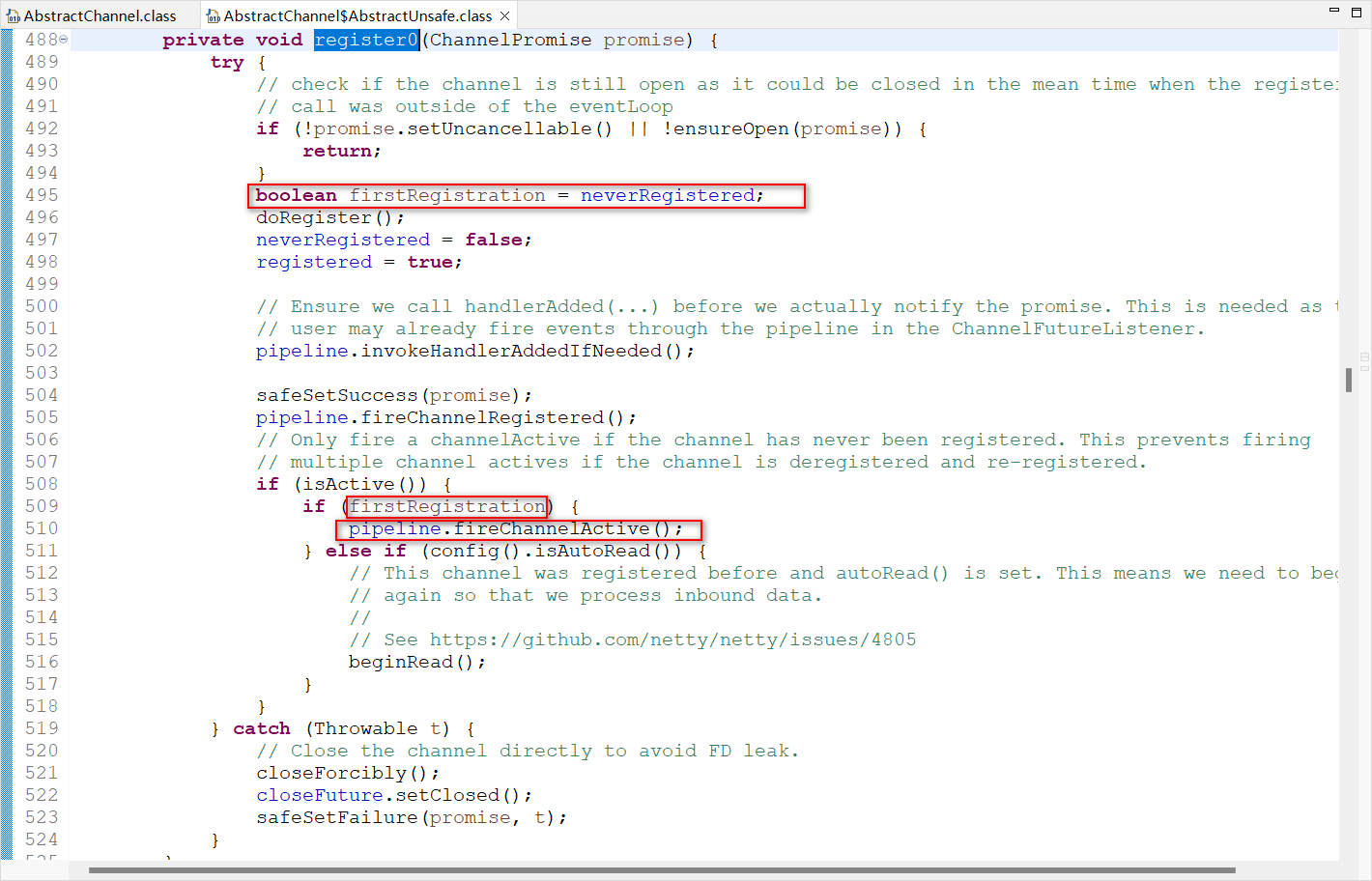
org.apache.dubbo.remoting.transport.netty4.NettyServerHandler.channelActive(ChannelHandlerContext)
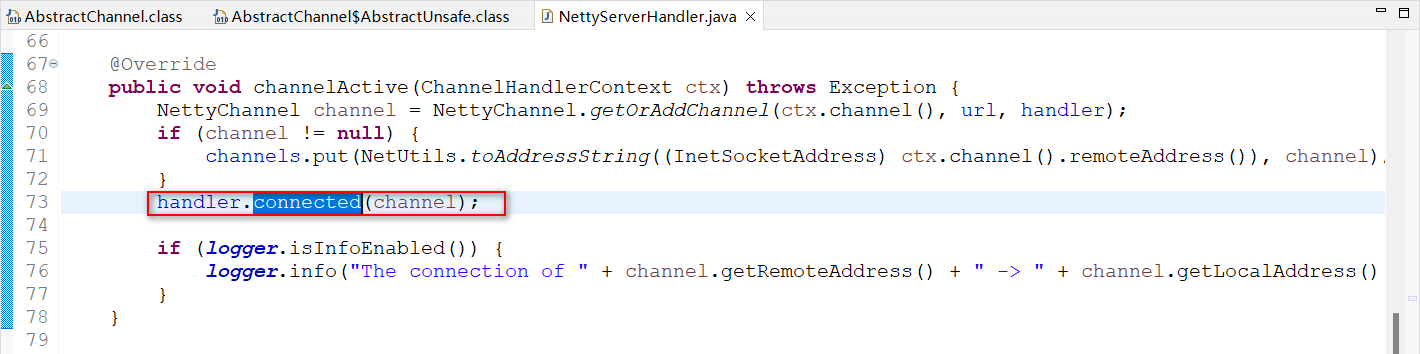
org.apache.dubbo.remoting.transport.AbstractServer.connected(Channel)
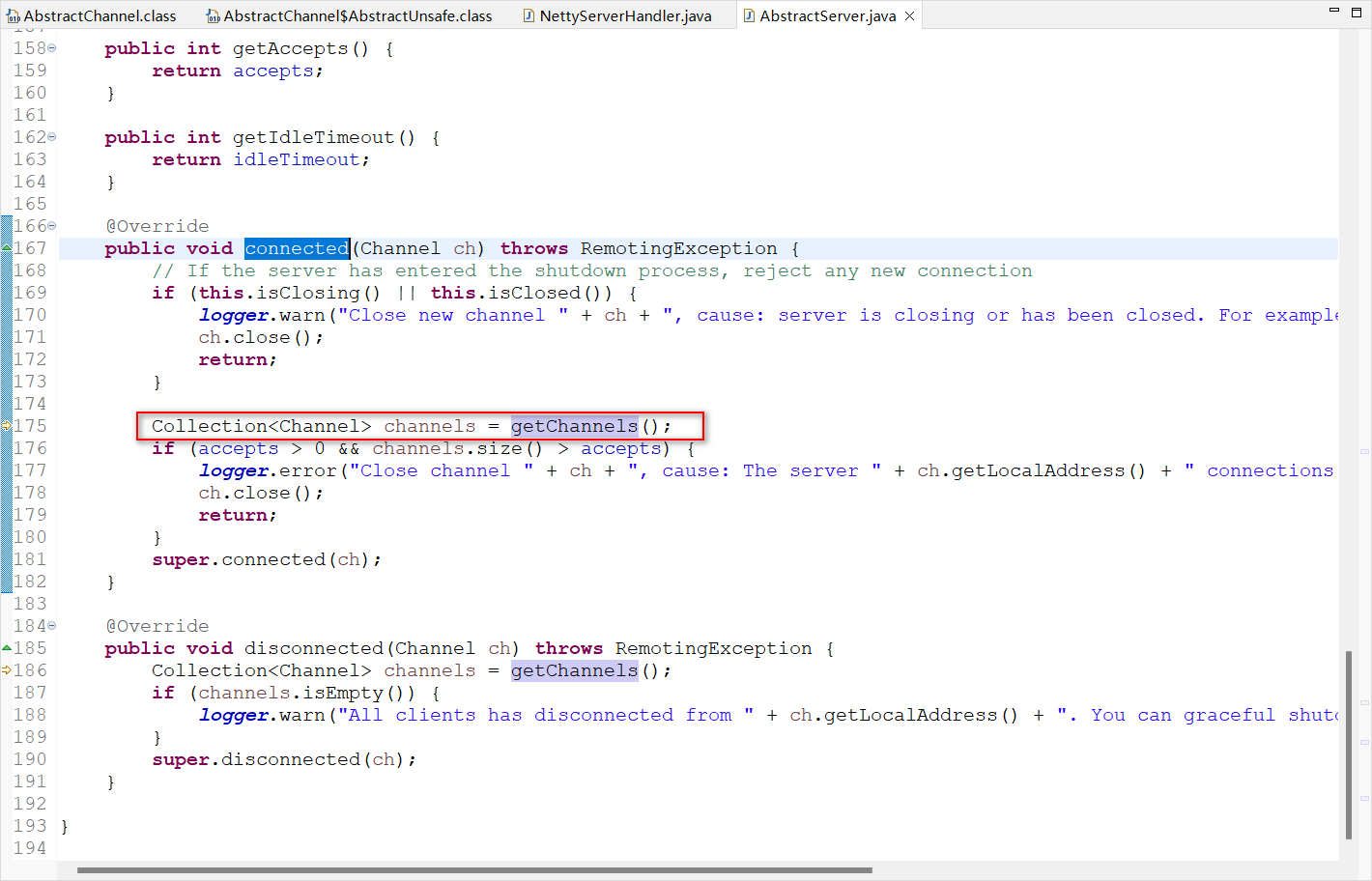
org.apache.dubbo.remoting.transport.netty4.NettyServer.getChannels()
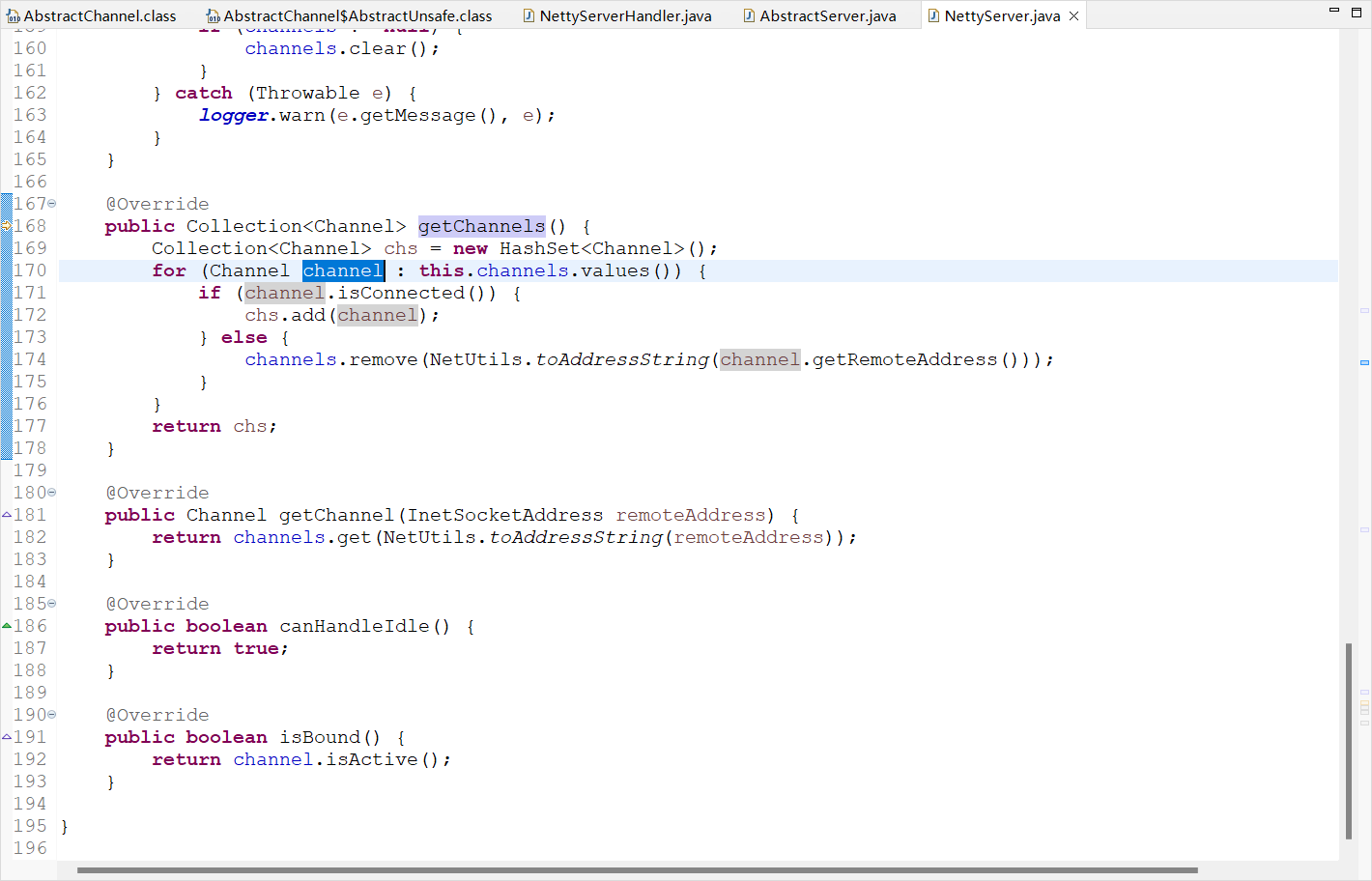
分析到NettyServer.getChannels这里,这段代码的大体逻辑很清晰,就是服务器(NettySeverHandler)在创建连接,在获取连接通道(getChannel)。
结合上述的线程信息、堆栈信息分析,我们于是提出一个疑点:为什么Dubbo会一直卡在建立连接的这一过程(这5条工作线程一直忙于或者卡在调用这一段代码),表现得像一个死循环,或者说,更像是一直不断在建立连接。
那么,排查思路被转到了:如何解答上述这个疑点?
我们反复通过若干的Arthas命令,前后来来回回反复排查约一天半,去定位上游不同的调用入口代码,试图从建立连接的上游找到突破口,去排查这个疑点,但基本没有头绪。
因为按正常逻辑,Dubbo只有在启动服务器时,与上下游建立连接(作为provider时与上游建立连接,作为consumer时则与下游建立连接),而这个连接是一个长连接,因为Dubbo协议默认使用单一长连接的方式来进行通信。
所谓单一长连接,就是指客户端与服务端之间只建立一个TCP连接,并保持长时间的有效性。在启动完成之后,长连接不会断开的,会一直保持。
所以按正常逻辑来理解,Dubbo不会自动断开连接再重新建立,也就是说不会出现上述这种“一直不断在建立连接”的类似“死循环”的现象。
又经过了一顿捣腾+观察,我们发现其实这一段并非死循环,而只是,只要持续有一个或两个请求进来,服务器的CPU就不会在短时间内降下来,就会出现CPU占高。或者,持续请求比较长时间,那么nety的任务队列里就会积累几十万的任务,我们通过arthas查看到netty的任务队列中存在着几十万个任务:
1 | vmtool--action getInstances --className io.netty.channel.nio.NioEventLoop --express‘instances.[#this.hashcode()+"--"+#this.taskQueue.size()}' --limit 10000 |
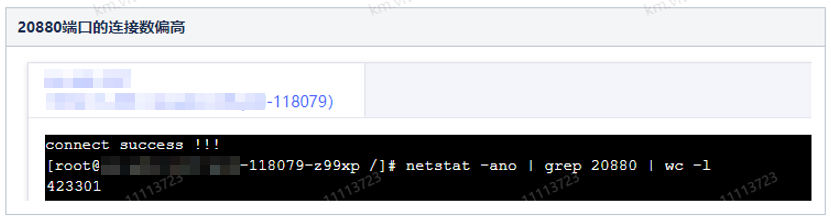
回顾回来,既然验证了CPU真的并非耗在一直假想的“死循环”上,那么猜测应该是存在着类似于遍历或迭代大集合这样的耗时处理,而又联想到netty任务队列里有40万+个连接任务(对应着dubbo端口占用40万+个TCP连接),就很容易心生猜想:代码里是否有遍历任务队列的操作从而导致耗CPU呢?此时再反复review回去之前的堆栈里所指向的那些模块的代码,终于发现了耗CPU的地方:
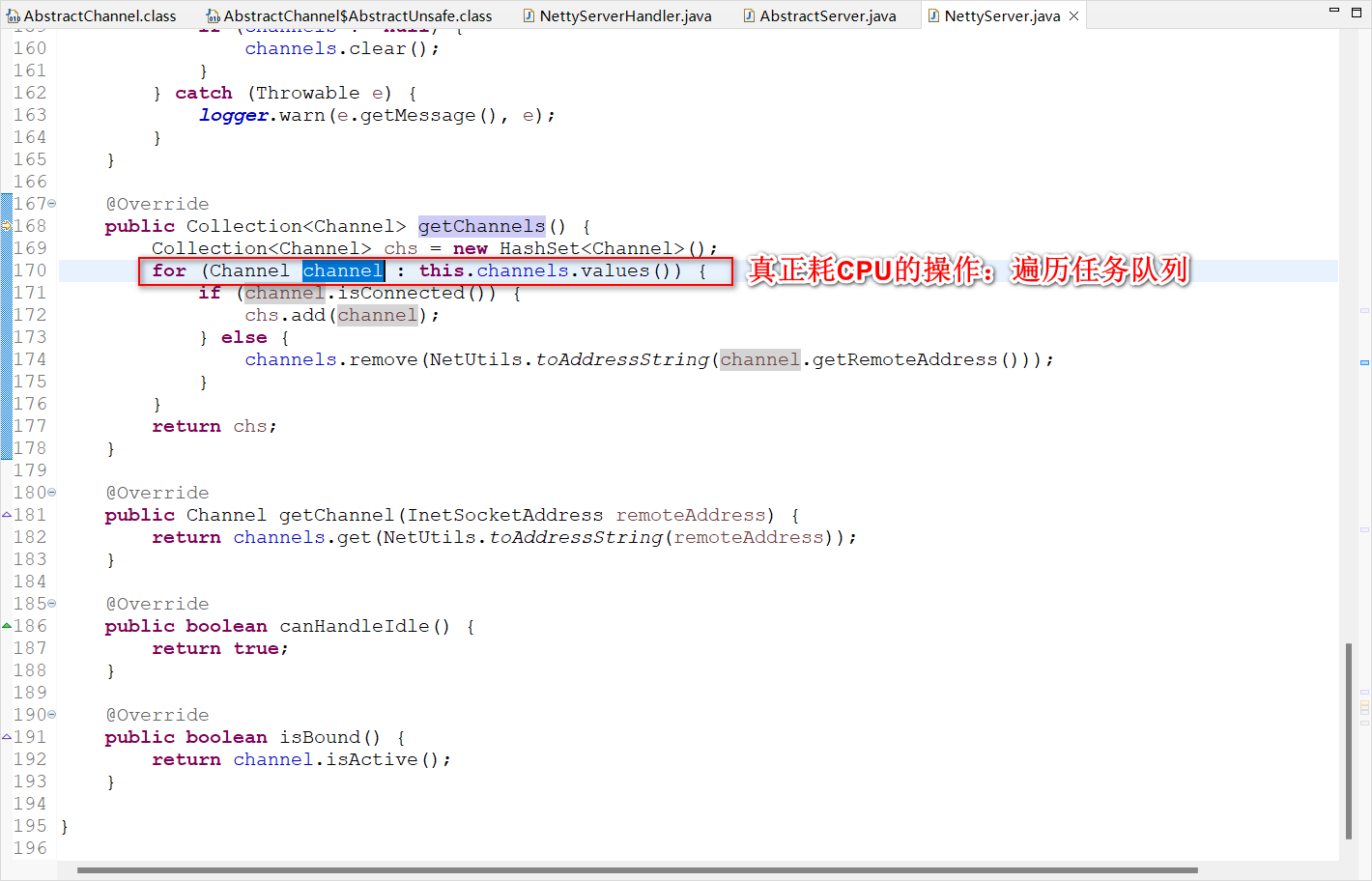
那么为什么,连接数会如此之大呢?
对dubbo的服务提供者(provider)的单台机器而言,【连接数=消费者实例数 × connections】,理解一下这里为何要乘以消费者实例数:是因为上游任何一个消费者consumer都可能跟提供者provider建立连接并产生调用。而在排查时,我们通过dubbo的动态配置页面上,查看到connections(连接池)配置成了300(如果不配置,默认值是1,也就是上文所述的默认上下游只建立1条长连接)。经过排查动态配置的操作记录,才得知,是较早之前团队里有开发同学手工误配成了300(他本人口述其实当时是想配置线程池=300,但配成了连接池=300)
至此,终于排查思路得以明朗,根本原因是出现在下游Dubbo服务器与上游的连接数量上,再结合排查时浏览的一些GitHub帖子,梳理一下前因后果,如下:
Dubbo的NettyServerWorker问题
NettyServerWorker问题·Issue #10492
dubbo HeaderExchangeChannel close method logic error· Issue #6902
代码分析
问题原因总结该问题的根因在于,由于动态配置项connections配置不当(误配成了300),并且因为对dubbo服务提供者(provider)单机器而言,【连接数=消费者实例数 × connections】,所以导致下游provider服务器的连接数太大。
而dubbo在重启(或者禁用后再启用)服务后,因为close()方法的bug导致禁用时没有实际关闭连接,并在重新启用后又再根据connections和消费者数量来决定建立大量的连接,由于服务器此时建立的连接的数量太多,最终导致netty的连接任务队列(channels集合)堆积严重,而在Dubbo内部的NettyServer中又存在着遍历channels的操作,因为遍历大集合比较耗CPU资源,所以CPU占用率就飙升,在持续一段时间后再叠加GC的操作,CPU耗费更严重,如此持续下来,内存占用率也疯涨,GC频繁但无效回收,最终也就导致了Out Of Memory,服务器最终崩溃。

解决方案
- Dubbo动态配置页面上,删除connections配置,恢复默认连接数1
- 升级dubbo组件版本至最新版本
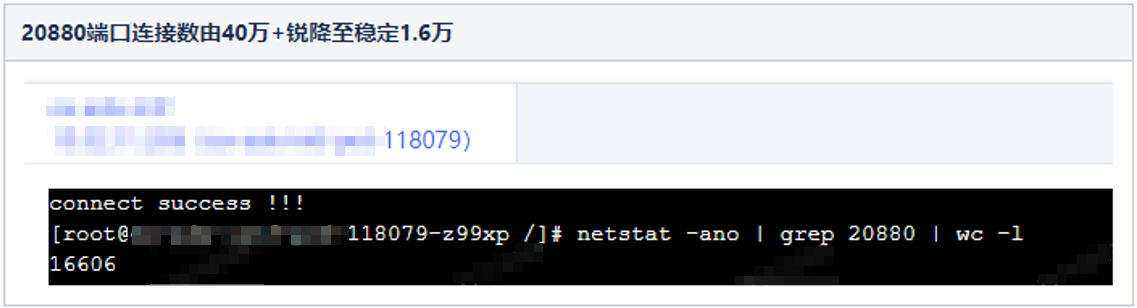
其中第1步操作后,效果立竿见影:
问题回顾
至此,回顾一下问题产生的背景,就不难理解了,此问题是在元旦时候临时扩容上游实例而得到触发、暴露,这是因为上游(consumer)做了扩容,导致上游的实例节点增加,而下游每个实例与上游建立的连接数量等于connections数值 × 上游实例数(即consumer数量),上游扩容一倍(节点数量相应增加了一倍),导致了下游(provider)的连接数扩大一倍,从而导致下游在重启(或禁用后重新启用)后,忙于处理连接任务队列里的channels集合的遍历,CPU一直占高,继而影响整体机器性能。
附录
扫描二维码,分享此文章